Introduction
The mkpy Python package provides transparent open access to human
and machine readable continuous and epoched EEG data for reproducible
analysis in scientific computing frameworks. mkpy is built around
an unopinionated EEG data interchange format (mkh5) that smoothly
and flexibly merges multichannel EEG data with the many other other
kinds of heterogenous experimental data required for single trial EEG
data analyses. The format is implemented in HDF5 which makes it
portable across scientific computing platforms within and between
labs.
Familiar problems
mkpy addresses problems that EEG researchers working with
open-source EEG data analysis toolboxes such as EEGLAB, ERPLAB,
Brainstorm, MNE Python likely have encountered or will.
The functional unit for EEG research is the experiment: subjects, stimuli, responses, dependent and independent variables. There are few principled bounds on the electrophysiological investigation of human information processing: what happens before, during, and after individuals are stimulated (if they are) and respond (if they do). The space of possible experimental designs and variables is vast and defined by the diversity of scientific aims and creativity of researchers.
The functional unit for EEG data analysis is the discrete time-series, longer or shorter stretches of digitized EEG data stored in one or more computer files. Analysis of discrete time-series data includes time-domain averaging along with other types of analysis: Fourier, wavelet, linear discriminant, principled component, independent component, multiple regression, multivariate pattern recognition, etc., etc., etc..
The functional unit for statistical analysis at present is the 2-D rows x columns data table e.g., data.frame, tibble, data.table for modeling in R; numpy.ndarray and pandas.DataFrame for modeling with statsmodels in python.
In the context of an EEG experiment, measures derived from signal processing transformations are but one variable among many. The problem, then, is how to knit all the relevant variables together into a data table so the statistical analyses can be conducted to answer the research question. This is not conceptually difficult, it is a form of database merge that combines and aligns values from heterogenous sources and exposes the result in a useful format. At present, however, the process is encumbered by the wide variety of binary EEG data file formats and data structures that have emerged over time as EEG data acquisition systems and open-source signal processing toolboxes have evolved.
Toward a solution
The mkpy framework shifts the focus in EEG data analysis away from
EEG signal processing data files and data structures and toward
experimental design and analyses as the functional unit.
Rather than trying to decide in advance what may, must, and cannot go
in EEG data file+header formats or in-memory EEG data structures, the
approach is to let experimenters make those decisions and concentrate
instead on making the files (mkh5) easy to work with regardless of
what data they contain and what scientific computing environment they
find themselves in. This approach is familiar from the concept of
human-readable text data interchange formats like Javascript Object
Notation (JSON) and YAML Ain’t Markup
Language (YAML): simple but
flexible (recursive) containers for arbitrarily complex content. The
Hierarchical Data Format v. 5 (HDF5) file specification is
a (less-simple) recursive container framework for binary data.
Likewise the mkh5 data model is also simple recursive container
format for data from EEG experiments: a single format for
continuous EEG, epoched single trial EEG, and the cornucopia of
non-EEG variables that must be knit together with the EEG data when
analyzing and interpreting designed experiments.
The format is familar: table-like blocks of time-series data travel with a dictionary-like header of keys and values. Simplification comes from enforcing a single, flexible format on the structure of the datablock and headers. Human and cross-platform machine readability comes from implementing the datablock as an HDF5 compound data type and the header as a single JSON string.
an interval of time is modeled by an uninterrupted series of fixed-rate digital samples with no temporal pauses, discontinuities, gaps, or boundaries. The interval may be short, e.g., 1 sample (a.k.a. “event”) or longer, e.g., 1000 samples (a.k.a “epoch”), or much longer (100000 samples, a.k.a. “continuous EEG”). These differ only in length not kind.
for a given interval of n samples there two kinds of experimental variables: those that change during the interval (the data streams) and those that do not (constants).
Data streams
Values that change during the interval are stored in a table-like block: rows (samples) x columns (data streams). Each data stream column is named, and each stream is of a single scalar data type: floating point, integer, unsigned integer, string, boolean. The number and data type of columns may vary ad lib.
Constants
Values that do not change during the interval are stored as a recursive key:value map terminating in data-typed scalars. The header travels with the data block and is encoded as a single utf-8 JSON string. Maps may be added to the header ad lib.
That’s it.
There is no “EEG data file format” per se. Instead there are a few simple rules (syntax) governing how the data in the data block and header are organized. The data streams that appear in the data block columns and the information embedded in the header are whatever the researcher finds useful for a particular purpose. And as these purposes change, the information that travels with the EEG data can change as well.
mkh5 files are constructed by translating a native EEG data
recording file into a sequence of one or more data blocks. The data
blocks can be arranged in the HDF5 file or files to suit the
requirements of the experiment. The data blocks from accidentally
split sessions with multiple data files can be glued back together
into a single file if needed. Long sessions can be split into
different mkh5 files. The data blocks can be organized into
separate files for each subject and analyzed separately or combined
into a single large file and analyzed together. Within a single file,
multi-session designs can be organized by nesting subjects in sessions
or sessions in subjects or not nested at all.
The tabular data block and the headers are both “stretchy” by design. Columns and header entries can be added or deleted provided only that the that the time-delta is constant between rows and the header tracks the name, index, and data-type of the data block columns. The JSON header can hold anything that JSON can encode which covers most of what experimenters generally need to track by way of experimental variables.
Once an mkh5 file is constructed, continuous or single-trial data
analysis of single subjects or entire experiments is greatly
simplified since there is no principled distinction between parts of
data files and whole data files or subjects and experiments. All of
these are the same data structure: a sequence of one or more
well-formed data blocks + header.
After the initial conversion to mkh5 no further import/export
parsers are required and cross-platform portability is immediate. By
using built-in functions or 3rd party hdf5 library wrappers, the
mkh5 HDF5 files can be read and written with a few lines of code
in Python, MATLAB, and R on linux, Mac OS, and Windows.
The mkh5 data block maps directly to data frames/tables in R,
Pandas, and MATLAB. The JSON header maps directly to native
structures, e.g., R named lists, Python dicts, and MATLAB
structs. This makes merging continuous and single-trial EEG data with
arbitrary non-EEG variables from other sources entirely
straightforward by taking advantage of existing table transformation
functions: row and column slicing operations by name or index to
access parts of a single table; table row and column stacking
operations to construct new tables; function application by row, by
column, and by group using column variables as the grouping factor.
Furthermore, any data the experimenter has embedded in the header or imported from an external source can be readily merged with the data block column EEG time-series and this can be whatever heterogenous information the experimenter deems useful, from recording session parameters and free-form experimenter notes to electrode locations, pre- and post-test scores, biomarkers, demographics, artifact screening criteria, etc., etc.. The JSON header format allows ready access to whatever information is traveling with the EEG data in the data block but does not require any particular header fields or content beyond the column index. Likewise the external data import also allows easy access to heterogenous information without requiring any of it. This flexibility allows the experimenter to smoothly marry the sampled EEG data to whatever sorts of experimental variables are useful for whatever sort of analysis is needed to answer research question.
In sum, the mkh5 approach is to define a simple, consistent
structure that is extensible in simple, consistent ways. The flexible
data blocks and headers can stretch as needed to accommodate very
different experimental designs and analyses while the consistent
format streamlines the development of what must inevitably be
semi-custom analysis pipelines.
mkpy overview
Although originally designed as a data interchange format for Kutas lab
binary ERPSS .crw and .log files, the file format is
unopinionated and EEG data from any system could be stored as mkh5.
In addition to database-like operations to create, update, and retrieve
mkh5 format HDF5 files, the mkpy package provides utilities for
visualizing and screening continuous and epoched EEG data
(pygarv), for tagging EEG data with experimental variables of
interest from the header and external data sources, and for exporting
single trial epochs is various data interchange formats for convenient
analysis.
mkh5EEG data (floating point), timestamps (unsigned int), event codes (ints), trigger lines, position sensor data, etc.., values change from sample to sample. These and other such data streams go in the tabular data block columns. Subject information, apparatus settings, etc. don’t change from sample to sample. That goes in the header.
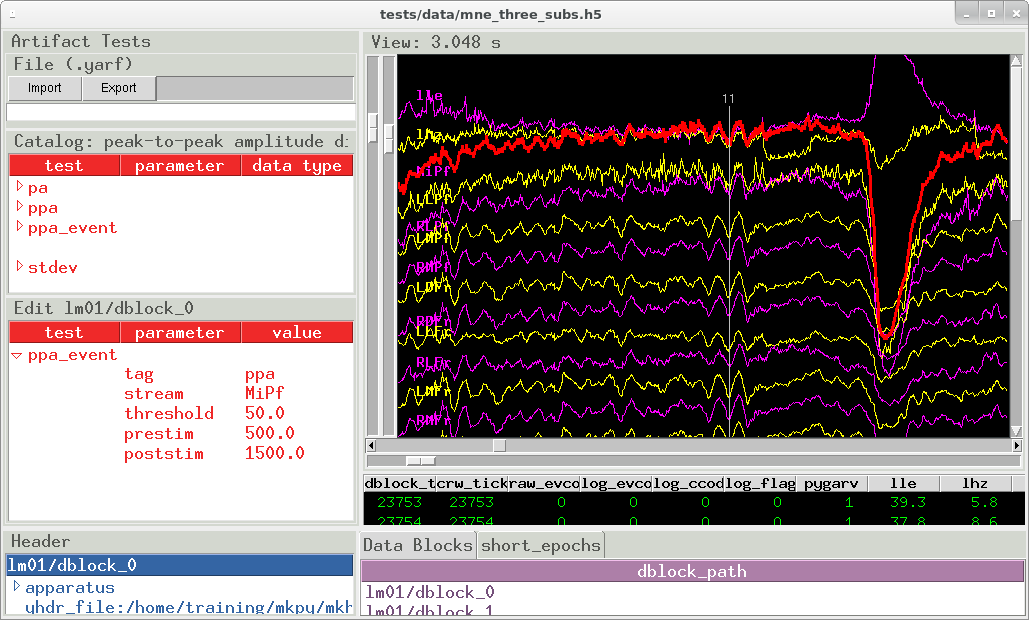
pygarv/mkh5viewerEEG artifact screening tests are stored on disk in human and machine-readable YAML. When the tests are applied, pass-fail results are logged in a datablock column so it travels with the data from then on. The tests and parameters themselves are stored in the datablock header. Tests can be viewed and edited interactively.
codetaggerArbitrary experimental design factors and levels are pulled from the header and/or imported from external YAML, Excel .xlsx, or tab-separated text and anchored to pattern-matched time-stamped integer event codes in the continuous EEG data before extracting single trial epochs and data reduction.
export_epochsThe tagged single-trial EEG data epochs can be exported in tabular format as HDF5, feather, or tab-separated text for downstream analysis.